
{kind=link}
Die Entscheidung für die Verwendung einer bestimmten Technologie ergibt sich häufig durch die Richtlinien und definierten Standards der Auftraggeber. Dementsprechend verfügen wir bei EMANO DEVELOPMENT über verschiedene Bereiche und Teams, die auf die einzelnen Technologien spezialisiert sind.
Onlineauswertung und Analyse von großen Datenmengen
Business Intelligence Lösungen helfen Ihnen bei der Identifikation und Integration relevanter Daten für Ihre Bereichs- und Unternehmenssteuerung und die Durchführung Ihrer Berichts-, Analyse- und Planungsaufgaben. Wir erstellen für Sie ansprechende Self-Service BI Dashboard-Lösungen auf Basis der folgenden Entwicklungssysteme: QlikView Analyse- und Reporting-System, SharePoint ggfs. mit Reporting Services sowie Excel ggfs. mit PowerPivot.
Aus technischer Sicht besteht der BI-Prozess auf den folgenden drei Phasen:
Phase 1: Data Delivery (Eckdatenerhebung, Schnittstellen zu operativen OLTP-Systemen, Data-Warehouse)
Phase 2: Discovery of relations, patterns and principles (Zusammenhänge, Muster und Diskontinuitäten herstellen)
Phase 3: Knowledge Sharing (Kommunikation und Verteilung des Wissens als Entscheidungsgrundlage)
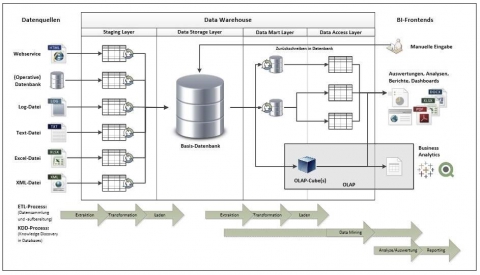
Die relevanten Daten für eine Analyse werden aus einem Data-Warehouse beziehungsweise Auszügen daraus (Data-Marts) gewonnen. Analysemethoden sind z.B. OLAP, Data-Mining, Text-Mining, Web-Mining oder Case-Based-Reasoning.
Die Bereitstellung und Überführung der operativen Daten in das Data-Warehouse ist von zentraler Bedeutung und geschieht im sogenannten ETL-Prozess (Extraktion-Transformation-Laden).
OLAP als multidimensionales Konzept setzt sich aus den Merkmalen Dimension, Measure, Hierarchie und Cube zusammen. Die Operationen sind Pivotierung, Roll-Up, Drill-Down, Drill-Across, Slice und Dice (Ad hoc).
Entsprechend Ihrer Anforderungen bezieht die BI-Lösung von Tableau in ihre Datenerfassung und -auswertung alle relevanten Systeme und Datenquellen mit ein. So analysieren Sie mit der Tableau-Software Ihre Daten einfach, schnell und flexibel mit einer hohen Aussagekraft.
Die Vorteile von BI-Lösungen mit Tableau:
- Sofortige Auswertung aller Daten
- Intuitive und einfache Bedienung
- Einfache Mechanismen zur Veröffentlichung
- Clevere Dashboards
Unter Berücksichtigung der einstellbaren Zugriffsrechte macht Tableau die Datenanalyse für jedermann möglich. Tableau eignet sich besonders für das Erstellen von Standardberichten und Vorlagen, setzt aber noch stärker auf die intuitive Benutzeroberfläche, die jederzeit schnelle und flexible Ad hoc-Auswertungen erlaubt.
Hadoop besticht insbesondere durch die Skalierbarkeit, so dass bei größeren Datenmengen lediglich mehr Rechner zur Verfügung gestellt werden müssen. HDFS, YARN und MapReduce sind ausgelegt auf die verteilte, parallele und fehlertolerante Verarbeitung von Daten, egal ob es sich um einzelne Rechner oder ein Cluster mit hunderten Nodes handelt.
Ein weiteres Argument für Hadoop ist die Vielzahl an Programmen, die auf den Kernkomponenten aufbauen. So ist es mit Hive möglich, die Daten auf dem Hadoop Cluster ähnlich wie in SQL als Tabellen zu speichern und zu verarbeiten. Andere hervorzuhebene Programme sind HBase, Kafka, Pig, Storm, ZooKeeper und insbesondere Spark, eine In-Memory Computing Engine, die statt MapReduce genutzt werden kann.
Oracle gehört zusammen mit Microsoft SQL Server sowie IBM DB2 zu den verbreitetsten kommerziellen relationalen Datenbank-Management-Systemen (RDBMS).
Als State-of-the-Art-Datenbank, die über viele Jahrzehnte kontinuierlich weiterentwickelt und verbessert wurde, bietet Oracle über seine Module Unterstützung für nahezu jeden denkbaren Use Case.
Oracle Module mit ihren Anwendungsgebieten:
- Oracle Application Express zur Entwicklung von schnellen und flexiblen web-basierten Anwendungen
- Oracle Spatial and Graph für Graphdatenbanken und Geoinformationen
- Oracle Multitenant Architecture mit einer Plug-and-play-Fähigkeit zum Austausch von Datenbanken
- Oracle XML DB und andere Module für die Unterstützung für semi- und unstrukturierte Daten wie XML und JSON
- Einbindung und Ausführung von Java-Sourcen und Klassen in der Datenbank
Oracle APEX ist eine kostenfreie Erweiterung der Oracle Datenbank und dient zur Erstellung von professionellen Web-Anwendungen. Mit APEX lassen sich sehr einfach Import/Export-Prozesse, Bearbeitungsmasken sowie Analysen und Reports erstellen.
Mit APEX können in kürzester Zeit effiziente und sichere Softwarelösungen entwickelt werden - und das ohne auf die Sicherheitskonzepte und Annehmlichkeiten einer Oracle Datenbank verzichten zu müssen. APEX ist optimal auf Ihre Oracle Datenbank abgestimmt.
Dadurch ergeben sich folgende Vorteile:
- APEX setzt direkt auf Ihrer Datenbasis auf
- APEX bietet hohe Performance
- APEX verfügt über kurze Entwicklungszyklen
- APEX ermöglicht ein einfaches Rapid Prototyping
Die Basis von APEX ist die leistungsstarke Oracle Datenbank, in die sich Ihre neue APEX-Anwendung nahtlos integriert. Nutzen Sie alle Features von einem der Marktführer unter den relationalen Datenbanken.
Verwenden Sie Tabular Forms, Master-Detail-Reports oder Diagramme. Exportieren Sie Ihre Daten in allen gängigen Formaten (CSV, PDF etc.). Durch Plugins und moderne Webtechnologien lässt sich Ihre Anwendung beliebig erweitern.
SAP Lumira ist eine Self-Service Business-Intelligence-Anwendung für Daten-Visualisierung.
Analysten können mit SAP Lumira zum Beispiel Datenstrukturen und Korrelationen ohne die Hilfe ihrer IT-Abteilung beliebig anpassen.
Es können sowohl unterschiedlichste Daten visualisiert als auch große Datenmengen analysiert werden.
SAP Lumira entstand aus dem SAP Business Explorer, dem früheren Self-Service Daten-Visualisierungs-Tool.
Apache Hadoop ist ein Framework zur hoch skalierbaren Speicherung und Verarbeitung von Big Data. Im Kern besteht Hadoop aus dem verteilten Dateisystem HDFS für die Speicherung sehr großer, möglicherweise auch sehr heterogener Dateien, dem Ressourcen-Management-System YARN, sowie aus MapReduce, einem System zur parallelen Verarbeitung der Daten.
Hadoop besticht insbesondere durch die Skalierbarkeit, so dass bei größeren Datenmengen lediglich mehr Rechner zur Verfügung gestellt werden müssen. HDFS, YARN und MapReduce sind ausgelegt auf die verteilte, parallele und fehlertolerante Verarbeitung von Daten, egal ob es sich um einzelne Rechner oder ein Cluster mit hunderten Nodes handelt.
Ein weiteres Argument für Hadoop ist die Vielzahl an Programmen, die auf den Kernkomponenten aufbauen. So ist es mit Hive möglich, die Daten auf dem Hadoop Cluster ähnlich wie in SQL als Tabellen zu speichern und zu verarbeiten. Andere hervorzuhebene Programme sind HBase, Kafka, Pig, Storm, ZooKeeper und insbesondere Spark, eine In-Memory Computing Engine, die statt MapReduce genutzt werden kann.
Apache Spark ist eine In-Memory Computing Engine für Big Data, die oft gemeinsam mit HDFS und YARN in einem Hadoop Cluster eingesetzt und statt der MapReduce-Engine genutzt wird, da Spark leichter verwendet werden kann und die Algorithmen auf lokale Verarbeitung im Hauptspeicher optimiert sind.
Spark bietet APIs für Java und Scala, aber auch für Python und R. Spark umfasst Komponenten für die Arbeit mit einem SQL-Interface ebenso wie zur Verarbeitung von Datenströmen. Zudem gibt es mit der MLlib eine sehr umfangreiche Bibliothek zum maschinellen Lernen, sowie mit GraphX Funktionen zur Arbeit mit Property Graphen. Die Verwendung von Spark reicht von Anwendungsfällen wie ETL-Prozessen, über interaktive Analysen hin zu Echtzeitdatenverarbeitung und High-Performance-Computing. Spark wird weltweit von namhaften Unternehmen eingesetzt, z.B. von Netflix, Alibaba, Samsung oder Goldman Sachs.
Teradata ist ein System zum Massive Parallel Processing (MPP), das in Enterprise Data Warehouse Plattformen und Lösungen für flexibles Datenmanagement eingesetzt wird.
Die wichtigste Eigenschaft des Systems besteht darin, dass es linear und voraussagbar skalierbar ist, und zwar in allen Dimensionen des Datenbank-Workloads (Datenvolumen, Anzahl Benutzer, Komplexität von Abfragen).
Aus diesem Grund wird Teradata in vielen groß angelegten Anwendungen unter Einsatz eines Data-Warehouse verwendet.
Nahezu alle ETL- bzw. BI-Tool Anbieter haben Kooperationen und Partnerschaften mit Teradata und bieten entsprechende Versionen der Software an.
Python ist eine interpretierende, dynamisch typisierte Multiparadigmen-Programmiersprache mit Konzentration auf objektorientierte und funktionale Programmierung. Da sie mit einem Fokus auf gute Lesbarkeit entwickelt wurde, ermöglicht sie eine sehr hohe Entwicklungsgeschwindigkeit, was auch durch das automatische Speichermanagement und eine sehr umfangreiche Standard-Bibliothek unterstützt wird.
Insbesondere besticht Python durch vielfältige und sehr hochwertige Web-Frameworks wie Django, Flask oder Pyramid sowie durch einen umfangreichen Data Science Stack. So hat sich Python durch Bibliotheken wie Numpy, Scipy, Pandas oder Scikit-Learn neben R zu einem führenden Tool in der Datenanalyse entwickelt. Dies umfasst einfache statistische Auswertungen und Visualisierungen, Anbindung von C, C++ oder Fortran Code sowie die Möglichkeiten des maschinellen Lernens bis hin zu Deep Learning Anwendungen mit TensorFlow.
Python kann auch sehr einfach als Scriptsprache in bestehende Anwendungen integriert werden.
R ist eine Open-Source-Programmiersprache, die vor allem im Bereich Data Science und in der Statistik eingesetzt wird. Während hier vor einigen Jahren SPSS und SAS die führenden Systeme waren, hat sich R durch seine einfache Programmierbarkeit, seine Flexibilität und seine hervorragende Erweiterbarkeit weltweit in führenden Unternehmen und Forschungseinrichtungen verbreitet und wird auf Desktop-Rechnern genauso wie auf High-Performance-Clustern verwendet.
Bei mehr als 12000 Paketen im Comprehensive R Archive Network gibt es kaum einen Algorithmus in der statistischen Datenanalyse, der nicht in R verfügbar ist. Auch die Anbindung von Code aus anderen Programmiersprachen, z.B. C, C++ oder Java, ist in R einfach möglich.
Zudem wird R seit einigen Jahren auch verstärkt direkt in Datenbank-Systeme eingebunden, so unter anderem in PostgreSQL, aber auch in kommerziellen Produkten wie dem Microsoft SQL-Server und Oracle. R zeichnet sich als domänen-spezifische Sprache von Statistikern für Statistiker aus, insbesondere aufgrund der Möglichkeiten zur interaktiven Datenexploration in der R Konsole, in RStudio oder mit dem Shiny Webserver, sowie hervorragender Visualisierungsbibliotheken wie lattice und ggplot2.
Eine Graphdatenbank ist eine NoSQL-Datenbank, in der Daten in Form eines Graphs mit Datensätzen als Knoten und Beziehungen zwischen den Datensätzen als Kanten modelliert werden.
Diese Modellierung bietet größere Flexibilität im Vergleich zu relationalen Datenbanken. Zudem sind Graphdatenbanken optimiert für effektives lokales Traversieren in einem Teilbereich des Graphen. Sie bieten sich insbesondere für sehr heterogene oder stark vernetzte Daten an. Die am weitesten verbreitete Graphdatenbank ist Neo4j, die sowohl lokal installiert, als auch in der Cloud, beispielsweise über MS Azure oder AWS, bereitgestellt werden kann.